RRDtool do třetice
Ponořil jsem se zase na nějakou dobu do RRDtool a konečně si spytlíkoval něco kloudného, pro mé potřeby zcela dostačujícího.
Nejdříve něco k tvorbě databáze. Opakování matka moudrosti, takže pěkně od začátku.
Databázi vytvořím v terminálu příkazem ve tvaru:
rrdtool create /cesta/soubor_s_databazi.rrd --step 60 --start cas_startu DS:nazev_promenne:DST:heartbeat:min:max DS:... RRA:CF:xff:step:rows RRA:...
Kde:
step - Krok, čas po kterém se budou zapisovat nové hodnoty do databáze ve vteřinách. Hodnota 60s je nejmenší rozlišovací hodnota CRONu, takže menší smysl asi nemá.
start - Parametr udávající čas, kdy se začnou sbírat data (v sekundách od 1.1.1970). Většinou postačí nahradit "N", což znamená hned (now).
DS určuje údaje o proměnné, která se má archivovat. Může jich být několik v jedné tabulce.
DS - Data Source, klíčové slovo, značící popis proměnné, která se bude zaznamenávat.
nazev_promenne - Název zaznamenávané proměnné.
DST - Data Source Type, typ proměnné. Může nabývat hodnot: COUNTER, DERIVE, ABSOLUTE, GAUGE. COUNTER bere rozdíl nynější a předchozí hodnoty (např. měření otáček, cpu, traffic). DERIVE, to samé co COUNTER, ale nabývá záporných hodnot (např. odchozí traffic). GAUGE, hodnota, co zjistí, to zapíše (např. využití RAM, swapu). ABSOLUTE jsem příliš nezkoumal, patrně vezme rozdíl aktuální a předchozí hodnoty a přičte ho k předešlé hodnotě, nevím.
heartbeat - Hodnota ve vteřinách, za jak dlouho se má indikovat NAN (Not A Number = není číslo), nebo UNK (UNKnown = neznámé). Například při vypnutí počítače, aby se nezakreslila do grafu nesmyslná hodnota, ale bylo tam prostě prázdno. Hodnota by měla být větší než step. Osobně se mi osvědčila hodnota 180s (trojnásobek pro --step 60).
min, max - Minimální a maximální hodnota, které mohou proměnné nabývat. Jinak se zapíše NAN nebo UNK. Pokud se použije znak 'U' (Unknown - neznámé), tak se to s tím popere nějak samo .-) Ale jak moc se spoléhat na automatiku nevím.
RRA definuje kolik hodnot bude tvořit jeden vzorek, jaká konsolidační funkce na něj bude použita, jak často se funkce provede...
RRA - Klíčové slovo, značící jak se budou ukládat posbíraná data.
CF - Consolidation Function, konsolidační funkce. Funkce, která se použije na vzorek posbíraných dat. Možnosti jsou AVERAGE (průměr z hodnot), MIN (minimum z hodnot), MAX (maximum z hodnot), LAST (poslední z hodnot).
xff - Procentuální zastoupení regulérních hodnot, od NAN nebo UNK ve vzorku, aby se ještě mohla použít konsolidační funkce a výsledek byl zapsán do databáze. Pokud bude procentuální zastoupení větší, bude výsledek vyhodnocen jako NAN nebo UNK. Bohužel už si nepamatuji, zda 0.6 znamená, že chybných nebo žádných údajů může být 60% a přesto se ze zbylých hodnot vyčaruje hodnota, která se zapíše. Nebo jestli správných údajů musí být 60%, aby se z nich dala vytvořit výsledná hodnota. Osobně jsem neměl problém s hodnotou 0.5 .-)
step - Počet hodnot tvořících vzorek, tzv. CDP (Consolidated Data Point). Ten se pak prožene konsolidační funkcí.
rows - Počet hodnot, které se budou zpětně archivovat.
Na --step, step(RRA) a rows dohromady závisí množství a četnost zaznamenávaných dat. Následně na tom pak také závisí velikost databáze.
Pro nejlepší přesnost zaznamenávaných hodnot nastavuji --step na 60s. Jednak se s tím ještě vypořádá CRON a druhak se s tím dobře počítá při výpočtu doby archivace.
Databáze všech měřených hodnot mají obdobnou strukturu. Proto popíšu jen jednu.
Rozhodl jsem se dělat šest grafů.
Dvouhodinový, 14-ti hodinový a denní, využívající stejný RRA záznam, nejpřesnější. U těch nastavuji step(RRA) 1. Tím se archivuje každá získaná hodnota. Rows jsem nastavil na 1500. Při získávání dat každou minutu to znamená archivace záznamů na 1500 minut, to znamená 1 den + 1 hodina. Dvouhodinový využívám jako náhledy na úvodní HTML stránce. 14-ti hodinový je nejpřesnější, co jsem schopen vytvořit. Určil jsem šířku tohoto grafu na 840 pixelů a když nechám zakreslit jednu hodnotu na 1 pixel, pak mi vyjde 14 hodin naměřených hodnot.
Časová rezerva archivovaných dat se určitě vyplatí, protože si RRDtool vybere samo vhodný RRA záznam, ze kterého vykreslí graf. Vybere automaticky nejpřesnější, který zároveň obsahuje data z celého, požadovaného, časového období grafu. Kdybych chtěl graf za poslední 2, nebo 24 hodiny, nebude problém. Pokud bych však kreslil graf za poslední 2 dny, pak by se použil jiný RRA záznam, který nebude tak přesný.
Týdenní RRA má step 5 a rows 2028. Vzorek se v tomto případě vytvoří z pěti hodnot sbíraných po 60 vteřinách (= 5 minut). Takovýchto vzorků bude archivováno 2028 (= 169 hodin = 7 dní + 1 hodina).
U měsíčního RRA nastavím step na 60 a rows na 750. To znamená, že vzorek tvoří 60 hodnot po 60 vteřinách (= 1 hodina), na které se použije konsolidační funkce. Archivovat se bude 750 vzorků, tj. 750 hodin (= 31 dní + 6 hodin).
Roční graf má nejmenší přestost. Step 720 a rows 732. Z toho plyne, že jeden vzorek se skládá ze 720 hodnot posbíraných po 60-ti vteřinách (= 12 hodin). Za den se tedy budou archivovat 2 hodnoty a na celý roční graf tedy bude třeba archivovat 730 hodnot (= 365 dní). S určitou rezervou tedy budu archivovat 732 hodnot (= 1 rok + 1den).
Po několika pokusech jsem došel k tomu, že pro mne má smysl pouze konsolidační funkce AVERAGE. MIN a MAX jsem zkoušel, ale pouze zcela zbytečně zabírají místo v databázi. Upřímně si nedovedu představit jejich reálné využití. Samozřejmě lze, aby se zobrazovali limitní hodnoty pod grafem, jenže graf kreslím s použitou konsolidační funkcí AVERAGE. Takže jednak maximální a minimální hodnota prostě nebude graficky zanesena. Druhak nikdo nezaručí, že naměřená hodnota nebude nějakým způsobem nesmyslná. Například mi jednou čidlo venkovní teploty ukázalo 71°C. V tom případě by se tato hodnota zobrazovala na ročním grafu rok. Samozřejmě že to lze oříznt maximální a minimální hodnotou, kterou proměnná může nabývat. Ale kde vzít jistotu, že když zvolím jako maximum 50°C pro případ léta, kdy čidlo může být na slunku, nějakým způsobem nenaměřím vadnou hodnotu 48°C v zimě? Z téhož důvodu vykresluji graf pomocí funkce AVERAGE, aby takovéto nesmyslné skoky díky průměrování byly odstraněny. Funkce LAST má stejný problém. Navíc u spousty grafů je minimální a maximální hodnota jasná. Například CPU určitě někdy poběží na 100% a tak podobně. Takže jsem usoudil, že bude užitečnější minimum a maximum průměrné hodnoty příslušného grafu :) Pro dvouhodinový graf jsem navíc schopen ošidit funkci LAST abych vypsal aktuální hodnotu. Tím, že u tohoto grafu mám krok 60 vteřin a vzorek obsahuje pouze jednu hodnotu, poslední hodnota je vlastně LAST :)
Jak jsem tedy již napsal, do databáze ukládám hodnoty pomocí konsolidační funkce AVERAGE. Dále se při tvorbě grafu dají zjistit MIN, MAX, AVERAGE a LAST hodnoty z již uložených hodnot v databázi za určené období. Toho se dá využít při kreslení grafů, konkrétně ke zjistění minima a maxima grafu.
A konečně příklad možného výsledeku jak vytvořit takovouto databázi:
rrdtool create /var/www/pat/rrdtool/rrd/jmeno_databaze.rrd --step 60 --start N DS:promenna1:COUNTER:180:0:200 DS:promenna2:COUNTER:180:0:200 DS:promenna3:COUNTER:180:0:200 RRA:AVERAGE:0.5:1:1500 RRA:AVERAGE:0.5:5:2028 RRA:AVERAGE:0.5:60:750 RRA:AVERAGE:0.5:720:732
Je samozřejmě nutné si upravit jmeno_databaze a počet, typ a nastavení měřených proměných.
Dále vytvořím skripty, které načtou proměnné, uloží je do databáze a vytvoří grafy.
Grafy získávám o vytížení CPU, teplotě CPU, vytížení sítě (zařízení eth0 a eth1), využití RAM, swapu, venkovní i vitřní teplotě a webové odezvě (ping).
Načítání proměnných závisí na tom o jakou hodnotu se jedná.
Vytížení CPU, využití RAM a podobně se dá zjistit pomocí SNMP daemona pomocí příkazu snmpwalk. Musí být však povolené čtení SNMP hodnot. To se nastavuje v /etc/snmp/snmpd.conf (platí pro Ubuntu), konkrétně řádky:
#sec.name source community com2sec paranoid default public #com2sec readonly default public #com2sec readwrite default privateje třeba změnit na:
#sec.name source community #com2sec paranoid default public com2sec readonly default public #com2sec readwrite default private(platí pro Ubuntu)
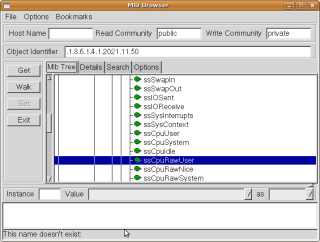
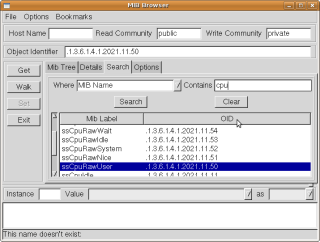
Na prohlížení, co všechno lze pomocí snmpwalku vyčíst, se dá použít program mbrowse (Ubuntu ho má v repozitáři), který má i funkci vyhledávání mezi možnými výsledky. [imgnoa]img41_mbrowse-01.png [imgnoa]img41_mbrowse-02.png
Snampwalk však nevrací jen požadovanou hodnotu, ale celý řetězec, ze kterého je třeba požadovanou hodnotu nějak extrahovat. Například k získání hodnoty využití procesoru jádrem vrátí snmpwalk:
pat@pat:~$ snmpwalk -v1 -c public localhost ssCpuRawSystem UCD-SNMP-MIB::ssCpuRawSystem.0 = Counter32: 194181
Potřebuji jen poslední číslo, takže použiji ještě nástroj cut. Podrobnosti viz manuál. Podstatné však je, že cut rozdělí řetězec, podle zadaného oddělovače a předá x-tou část takto rozděleného řetězce. Parametr -d zadá odělovač a -f číslo části, která mne zajímá. V případě:
pat@pat:~$ snmpwalk -v1 -c public localhost ssCpuRawSystem | cut -d" " -f4 196020je oddělovačem mezera a zajímá mne čtvrtý kousek rozděleného řetězce.
Došel jsem k následujícím skriptům:
Ping
Teplota procesoru
Teplota okolí
Vytížení sítě - eth0
Vytížení sítě - eth1
Využití RAM
Využití swapu
Zatížení procesoru
Skripty obsahují i zakomentovaný příkaz k vytvoření konkrétní databáze.
Jsou si navzájem dost podobné. Výsledné grafy nechávám vykreslit tak, aby se mi seděli do primitivní HTML stránky (nejsou aktualizovány).
U teploty okolí a pingu používám dvě databáze. Mám dvě čidla a každé má svou databázi. To kdybych se v budoucnu rozhodl přidělat další čidlo teploty, nemusím rušit stávající databázi, ale prostě nechám do grafu zakreslit hodnoty z další databáze. Zakreslit do jednoho grafu hodnoty z několika, klidně nesouvisejících, databází totiž není problém. Stejně tak ping testuju na dva servery, tak má každý svou databázi.
U vytížení sítě jsem nevyužil pro upload typ DERIVE. Sice do grafu kreslím zápornou hodnotu, takže musím vytvořit novou proměnnou, která je negací původní. Jenže také vypisuji hodnotu a tam nechci záporné číslo, takže bych novou, negovanou proměnou musel beztak použít. Pokud bych chtěl jenom kreslit a nevypisovat, tak bych DERIVE použil.
Zatížení procesoru u vícejádrových procesorů se musí ošetřit. Dvoujádrový procesor nemá maximum 100%, ale 200%. Nevím proč, ale snmpwalk nevrací hodnoty, nebo jsem to alespoň nenašel, pro jednotlivá jádra, ale pro celý procesor najednou. Takže aby se do grafu zaneslo logických 100%, musí se získané hodnoty vydělit dvěma (pro 2-jádrový procesor).
Hodnoty o teplotě okolí získávám pomocí digitempu (Ubuntu ho má v repozitáři) ze dvou externích čidel.
Aktuální hodnoty měřených veličin samozřejmě vypisuji pouze u nejpřesnějšího grafu. U ostatních to jednak nemá smysla druhak už by to vlastně nebyla poslední měřená hodnota. U ostatních grafů už je poslední hodnotou průměrná hodnota ze vzorku x hodnot. Ještě by to šlo u grafu za den, ten používá stejný RRA záznam, pravda, ale vzhledem k přehlednosti grafů jsem to nechtěl komplikovat .-)
Všechny skripty mám v adresáři /etc/cron.rrdtool/ a spouštím je automaticky každou minutu CRONem. Stačí jako:
pat@pat:~$ sudo crontab -e
A po vyplnění správného hesla zadat:
*/1 * * * * /bin/run-parts /etc/cron.rrdtool/ >> /dev/null
Tím se spustí run-parts, který spustí všechny skripty v adresáři. Pokud jsem měl skripty pojmenované tak, že měli přípony .sh, tak je run-parts nedetekoval a nespustil. Nevím proč, spustitelné byly. Ale bez přípony je spouští, tak jsem spokojen :)
Nic dalšího mne nenapadá, takže ještě pár postřehů.
DEF označuje definici proměnné, která se bude používat. To znamená specifikaci databáze a proměné z databáze jejíž data mne zajímají. Následuje výběr konsolidační funkce, která byla použita na sbírané vzorky. Pokud tedy sbírám data a ukládám hodnoty ze vzorků na které používám AVERAGE, nemůžu v definici žádat o LAST. Jednoduše v databázi neexistuje taková proměnná.
CDEF zase slouží k definici dalších proměnných, které nejsou v databázi. Například pokud potřebuji získat negaci nějaké hodnoty. Jednoduše se určí název proměnné, konstanty nebo proměnné, ze kterých se spočítá a řádek zakončí znaménko, které se k má použít. Například:
CDEF:realcpu_user=cpu_user,2,/
Vytvoří novou proměnnou jménem realcpu_user, kterou získám vydělením proměnné cpu_user (ta musí být definována výše) dvěma. Před znaménkem je nutné zadat znak ''.
Číslo za slovem LINE sílu čáry. Například LINE2 vykreslí čáru tlustou 2 pixely.
Při psaní do grafu používám %#.#lf, kde '#' nahrazuji číslem. Znamená to, že např: %3.1lf vypíše požadovanou hodnotu na tři čísla s přesností na 1 desetinné. Do počtu 3 se však počátá jak desetinná čárka, tak číslo za ní. Dělalo mi to bordel hlavně při pokusech o zarovnání do tabulky.
Pro automatickou korekci jednotek (kilo, Mega, ...) se dá zase použít %S. Např: "...%6.1lf %SB/s...". Výslekem je automatická změna B/s, kB/s, MB/s například u vytížení sítě.
Dva nové prázdné řádky je nutno zapsat jako:
... COMMENT:" \n" COMMENT:" \n" ...
Jiná varianta mi neprošla. Druhý řetězec "\n" je ignorován, ať před něj dám mezeru, nebo ne.
Odsazení tabelátory "\t" může být za sebou několikrát v jednom výrazu, s tím není problém.
Další poučné čtení je popis rrdgraph_graph na domovských stránkách RRDtool. Dokumentace výrazně posílila od doby, kdy jsem tam byl naposled. Dle letmého shlédnutí se dá nějak změnit i font, barva a podobné vymoženosti. To jsem však nezkoušel, už jsem se stávajícím stavem spokojen a pravděpodobně s RRDtool končím :)
Ještě odkaz na zabalené spouštěcí skripty a jednoduché HTML stránky s grafy.
Náhled na výsledné grafy pomocí primitivní HTML stránky (nejsou aktualizovány).
Aktualizace 29.4.2010:
Doplněno o skript na zjišťování a záznam teploty disků. Je k tomu využita utilita HDDTemp.
Teplota disků
V tomto případě se jedná o záznam teplot čtyř disků. Potřeba k tomu je vytvoření také čtyř databazí, stejně jako u ostatních skriptů je vzor pro tvorbu jedné databazáze zakomentován na začátku skriptu.
|
|
|
|
|
|
|
|
|
|